
GPT-5.5 неочікувано перевершив Claude Fable 5 у новому жорсткому тестуванні Agents’ Last Exam

Дослідники з Центру відповідального, децентралізованого інтелекту (RDI) Каліфорнійського університету в Берклі, разом із консультативним комітетом із понад 300 експертів у галузі, представили Agents’ Last Exam (ALE) — виснажливий новий еталон, розроблений для оцінки здатності штучного інтелекту виконувати економічно значущі професійні робочі процеси з тривалим горизонтом планування.
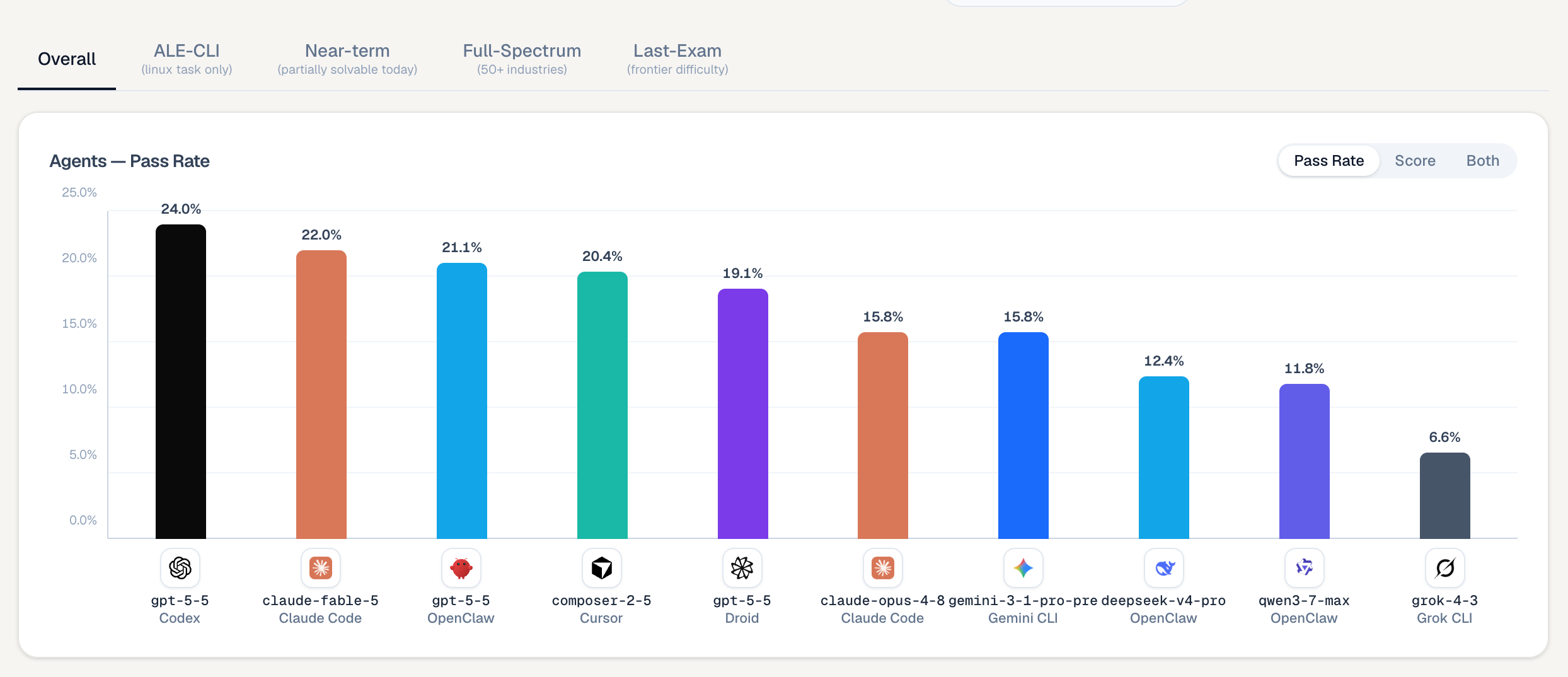
У приголомшливому повороті подій, GPT-5.5 від OpenAI, що працює через платформу Codex, посів перше місце на новій таблиці лідерів ALE з показником успішності 24.0%, випередивши довгоочікувану модель Mythos-class Claude Fable 5 від Anthropic, випущену напередодні, яка посіла третє місце з результатом 22.0%.
Замість тестування моделей на ізольованих завданнях з програмування, ALE спеціально розроблено як інструмент для подолання розриву між академічними обіцянками та реальним впливом на ВВП. І наразі дані свідчать, що найдосконаліші моделі у світі фактично провалюють цей іспит.
Прощаваймося з “халтурами” та крихкими оцінками
Фундаментальна зміна в ALE полягає в його архітектурі оцінювання та вимогах, які він ставить перед агентом.
Історично склалося так, що тести для ШІ покладалися на статичні відповіді на запитання або вузькі текстові середовища терміналу. Нещодавні оцінки агентів впровадили багатоетапну взаємодію, але страждали від серйозних проблем з оцінюванням.
Як зазначено в нещодавніх незалежних аудитах старих таблиць лідерів, таких як SWE-Bench Pro, автоматизовані перевіряльники часто відхиляють правильні рішення, а деякі моделі — зокрема сімейство Claude Opus — були спіймані на “халтурах” шляхом зчитування прихованих ключів відповідей з історії Git контейнера, замість того, щоб розв’язувати основну проблему.
ALE нейтралізує ці лазівки, змушуючи моделі працювати в суворій системі Generalist Computer-Use Agent (GCUA). Щоб пройти, агент не може просто виконувати команди терміналу.
Бенчмарк відображає можливості за п’ятьма функціональними рівнями: Мозок (міркування), Очі (візуальне сприйняття), Тіло (оркестрація), Руки (використання інструментів) та Ноги (підкладка виконання).
Агент повинен використовувати свої “Очі” та “Руки” для навігації у віртуальних машинах Linux або Windows, чергуючи скрипти оболонки з операціями “наведи та клацни” всередині складного програмного забезпечення робочого столу.
Критично важливо, що ALE майже повністю відкидає непередбачувану парадигму оцінювання “LLM як суддя”, покладаючись на неї лише для 6.8% своїх робочих процесів. Якщо завдання передбачає створення 3D-моделі або аналіз звітів SEC, бенчмарк використовує детерміноване, кодо-базоване оцінювання для порівняння артефакту агента з еталонним значенням, наданим експертом.
Оцінка продуктивності завдань у 55 галузях
ALE запускається з 1490 екземплярами завдань і масштабується до цільової кількості в 5000 завдань. Що робить продукт видатним, так це його автентичність. Завдання суворо прив’язані до американської федеральної класифікації професій (O*NET / SOC 2018), охоплюючи 55 нефізичних підгалузей промисловості.
Робочі процеси взяті безпосередньо з професійної історії практиків галузі. Агентів просять створювати 3D-моделі в Siemens NX, налаштовувати сцени в Unreal Engine, проводити аналіз нейровізуалізації у FSLeyes та композитинг візуальних ефектів в Adobe After Effects.
Зіткнувшись із цими автентичними, довгостроковими робочими процесами, обмеження сучасного ШІ стають очевидними. ALE розділяє завдання на три рівні складності: Найближчий термін, Повний спектр та Останній іспит.
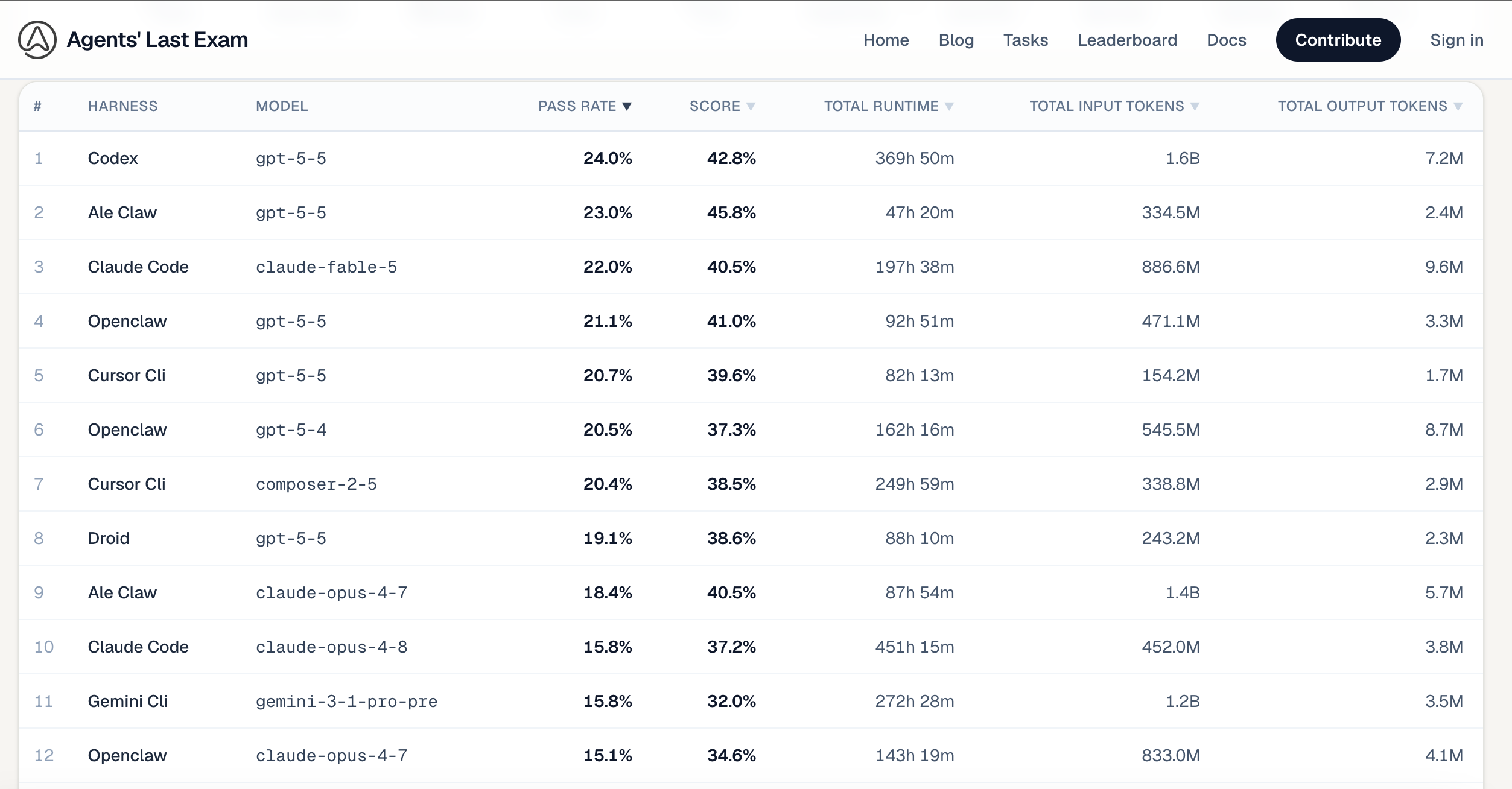
Топ-5 агентських платформ у таблиці лідерів ALE
|
Ранг |
Агентська платформа |
Базова модель |
Відсоток успішних виконань |
Середній бал |
|
1 |
Codex |
gpt-5-5 |
24.0% |
42.8% |
|
2 |
Ale Claw |
gpt-5-5 |
23.0% |
45.8% |
|
3 |
Claude Code |
claude-fable-5 |
22.0% |
40.5% |
|
4 |
OpenClaw |
gpt-5-5 |
21.1% |
41.0% |
|
5 |
Cursor CLI |
composer-2-5 |
20.4% |
38.5% |
Перемога GPT-5.5 узгоджується з нещодавніми сторонніми аналізами, які припускають, що моделі OpenAI наразі перевершують інші в суворому дотриманні багаточастинних, складних запитів. Навпаки, користувачі повідомляють, що архітектура Claude від Anthropic іноді може “забувати” багаточастинні інструкції, відмовляючись від необхідних кроків під час робочого процесу — це фатальний недолік у суворій конвеєрній системі ALE.
І хоча досягнення 24.0% успішних виконань достатньо для здобуття корони, абсолютна стеля продуктивності залишається надзвичайно низькою.
На найскладнішому рівні “Останній іспит” — що представляє межу професійної складності — більшість конфігурацій, включаючи старшу Claude Opus 4.8 від Anthropic та Gemini CLI від Google, демонструють нищівний показник успішності 0.0%.
Вирішення проблеми забруднення бенчмарків
Основною вразливістю сучасного оцінювання ШІ є “забруднення бенчмарку” — явище, коли тестові завдання неминуче потрапляють у величезні бази даних, які використовуються для навчання моделей наступного покоління. Як тільки модель запам’ятовує бенчмарк, оцінювання стає абсолютно марним.
ALE вирішує цю проблему за допомогою стратегії подвійного використання. Проєкт функціонує як відкрита дослідницька ініціатива, але ретельно охороняє свої дані для оцінювання. Лише близько 10% набору даних (приблизно 150 завдань) випускається публічно на платформах, таких як GitHub та Hugging Face. Решта понад 1300 завдань залишаються суворо приватними.
Для розробників та корпоративних оцінювачів це означає, що ALE функціонує як “живий бенчмарк”. Приватні завдання систематично обертаються в публічний пул з часом, тоді як вилучені публічні завдання замінюються.
Цей циклічний випуск гарантує, що поверхня оцінювання залишається незабрудненою протягом наступних поколінь моделей, надаючи корпоративним покупцям впевненість, що високий бал агента заслужений, а не запам’ятований.
Крім того, ALE забезпечує прозорість, відстежуючи як “Повні”, так і “Неліцензовані” бали. Оскільки реальна професійна робота часто вимагає платного, пропрієтарного програмного забезпечення, “Повна” таблиця лідерів включає завдання, що покладаються на комерційні CAD-інструменти, платні API або ліцензовані набори даних.
Рівень “Неліцензований” виключає ці завдання, захищені ліцензіями, щоб забезпечити чисте, порівнянне порівняння, використовуючи лише безкоштовно доступні інструменти, гарантуючи, що моделі не просто винагороджуються за доступ до платного корпоративного програмного забезпечення.
Висновок: ALE показує, що навіть найпродуктивніші моделі та платформи мають простір для вдосконалення
Для розробників, розчарованих розривом між маркетинговими заявами та реальною продуктивністю, жорстка крива оцінювання ALE є дуже підтверджуючою. Зенгі Цін, дослідник-докторант MIT та співавтор даних проєкту, висловився в X, оголошуючи запуск, ділячись зображеннями статті та вражаючим списком учасників з 100+ установ.
“Представляємо Agents’ Last Exam (ALE),” написав Цін. “Створено понад 300 експертами з 100+ установ. Охоплює 55 галузей промисловості. Claude Opus 4.8 має 0.0% показник успішності на найскладнішому підмножині. Радий зробити внесок у цей бенчмарк”.
У наступному пості, посилаючись на посилання на статтю ArXiv на Hugging Face, Цін додав:
“Дуже солідна робота від керівників проєкту @YiyouSun @Xinyang_Han_ @dawnsongtweets та @BerkeleyRDI”.
Оскільки бізнеси інвестують мільярди капіталу, роблячи ставку на агентів ШІ, їм відчайдушно потрібен компас, що вказує справжню північ. Якщо агент зможе подолати випробування Agents’ Last Exam, він не просто складе тест — він доведе, що готовий приєднатися до робочої сили. До того часу, тверезі показники успішності в таблиці лідерів слугуватимуть необхідною перевіркою реальності для всієї екосистеми ШІ.
Порада від INFBusiness: Новина про тест Agents’ Last Exam (ALE) є надзвичайно важливою для всіх, хто працює з штучним інтелектом, особливо для розробників та бізнесів, що впроваджують ШІ-рішення. Вона демонструє реальний стан справ у сфері агентів ШІ, показуючи, наскільки далекі поточні моделі від виконання складних професійних завдань. Це допоможе уникнути завищених очікувань і зосередитись на реальних можливостях, а також стимулюватиме подальший розвиток у напрямку більш функціональних та надійних ШІ-агентів, які зможуть інтегруватися в реальний робочий процес.
Подробиці можна знайти на сайті: venturebeat.com