

Китайська ШІ-компанія DeepSeek представила анонс нового покоління лінгвістичних моделей. Найкраща V4-Pro перевершила Claude Opus 4.6 і GPT-5.4, ставши передовою відкритою системою.
🚀 Оголошення DeepSeek-V4 офіційно представлено і з відкритим кодом! Вітаємо в епоху доступного контексту на 1 млн токенів.
🔹 DeepSeek-V4-Pro: 1,6 трлн в цілому / 49 млрд активних параметрів. Продуктивність на рівні провідних закритих моделей у світі.
🔹 DeepSeek-V4-Flash: 284 млрд в цілому / 13 млрд активних параметрів.… pic.twitter.com/n1AgwMIymu— DeepSeek (@deepseek_ai) 24 квітня 2026
Структура та розмір
V4-Pro містить приблизно 1,6 трлн параметрів, але на кожному етапі застосовує лише 49 млрд. У другій версії — V4-Flash — загальний розмір становить 284 млрд, з яких активуються 13 млрд.
Обидві моделі базуються на архітектурі «суміші експертів» (Mixture of Experts, MoE): під час опрацювання кожного токена задіюється тільки відповідна частина підмереж. Такий підхід більш економічний, ніж повністю щільні структури, але не поступається їм за ефективністю.
Початкове навчання відбулося на наборі даних обсягом понад 32 трлн токенів. Потім розробники поступово донавчали моделі, виділивши окремі блоки для кодування, математики, логіки та виконання інструкцій. Остаточна версія об’єднує ці навички за допомогою дистиляції.
Тривалий контекст став вигіднішим
Головною особливістю V4 стала оптимізація обробки довгих послідовностей. Контекстне вікно в 1 млн токенів є і в інших моделей, але його застосування зазвичай супроводжується значними витратами та затримками.
У DeepSeek повідомили, що нова версія відчутно зменшила витрати ресурсів на такі операції. У порівнянні з V3.2, V4-Pro вимагає приблизно 27% обчислень і 10% пам’яті KV-кешу під час роботи з максимальним контекстом. Для V4-Flash показники становлять близько 10% і 7% відповідно.
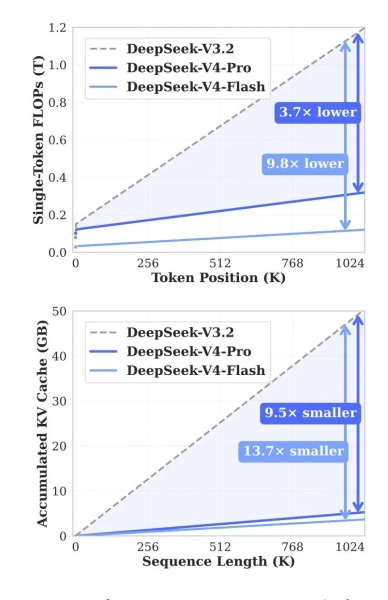
Джерело: Hugging Face.
Команда досягла результату завдяки гібридній архітектурі уваги: два механізми стискають інформацію та знижують навантаження при роботі з великими текстами. Також застосовано спеціальні гіперзв’язки для стабільності та оптимізатор Muon для прискорення навчання.
Режими розмірковування та агентні можливості
DeepSeek V4 підтримує три режими розмірковувань:
- Non-think — швидкі відповіді на прості питання без додаткового розгляду.
- Think High — глибокий аналіз для складних завдань і планування.
- Think Max — максимальний режим: модель обробляє кожен етап і перевіряє всі варіанти.
В агентних задачах режим Max тепер зберігає послідовність проміжних кроків у рамках одного завдання. У попередній версії частина такого контексту втрачалася під час взаємодії з користувачем.
Результати тестувань
Згідно з даними DeepSeek, флагманська версія демонструє результати, порівнянні з передовими системами у багатьох напрямках:
- у завданнях з програмування на Codeforces модель отримала рейтинг 3206 — 23-тє місце серед активних програмістів світу, паритет з GPT-5.4;
- в математиці показала 95,2 на HMMT 2026 і 89,8 на IMOAnswerBench, обігнавши більшість конкурентів;
- у знаннях SimpleQA Verified — 57,9 (Opus 4.6 — 46,2, але Gemini 3.1 Pro — 75,6).
- у reasoning моделі відстають від GPT-5.4 і Gemini 3.1 Pro лише на три–шість місяців;
- у внутрішньому тесті DeepSeek, що включає розробку, налагодження та рефакторинг, модель досягла 67% — між Sonnet 4.5 (47%) і Opus 4.5 (70%);
- в агентних сценаріях і завданнях розробки V4-Pro-Max продемонструвала 80,6% на SWE Verified і 67,9% на Terminal Bench.
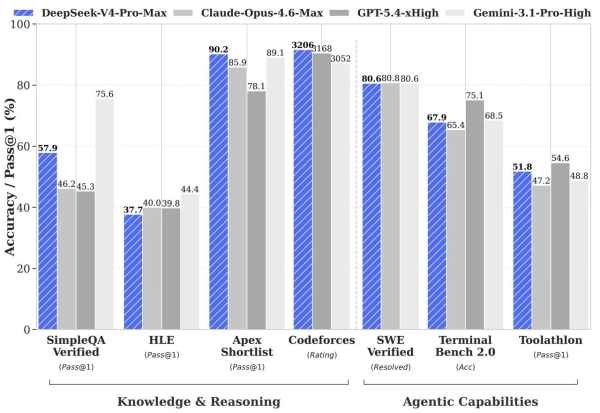
Джерело: Hugging Face.
V4 спеціально навчали на реальних сценаріях: аналіз даних, створення звітів, редагування документів, пошук в інтернеті з ітеративним використанням інструментів.
Для оцінки придатності моделі в реальній розробці стартап провів внутрішнє тестування на завданнях своїх інженерів. В опитуванні 85 розробників і дослідників 52% повідомили, що готові використовувати V4-Pro як основну модель для кодування, а ще 39% відзначили, що схиляються до такого рішення.
Нагадаємо, 23 квітня компанія OpenAI випустила GPT-5.5. Модель позиціонується як «новий рівень інтелекту для практичної роботи та управління агентами».